
Function Block Friday: Queue Buffers
This week, we’re diving into Buffers as Function Blocks. Buffers are essential elements of many robust systems for ensuring actions and data in asynchronous environments are dealt with. Though simple in concept buffers can be deceptively difficult to code robustly and efficiently, especially for memory-constrained applications.
Lucid offers a range of buffer types including First-In-First-Out (FIFO), and Last-In-First-Out (LIFO).
Queuing buffers are conventionally modelled as push and pop functions, where push adds an element to a queue and pop extracts and removes one at a time. Buffer may also need to be flushed of all content and started again. These functions are presented in Lucid by the usual event and data port constructs.
Let’s look at a couple of examples:
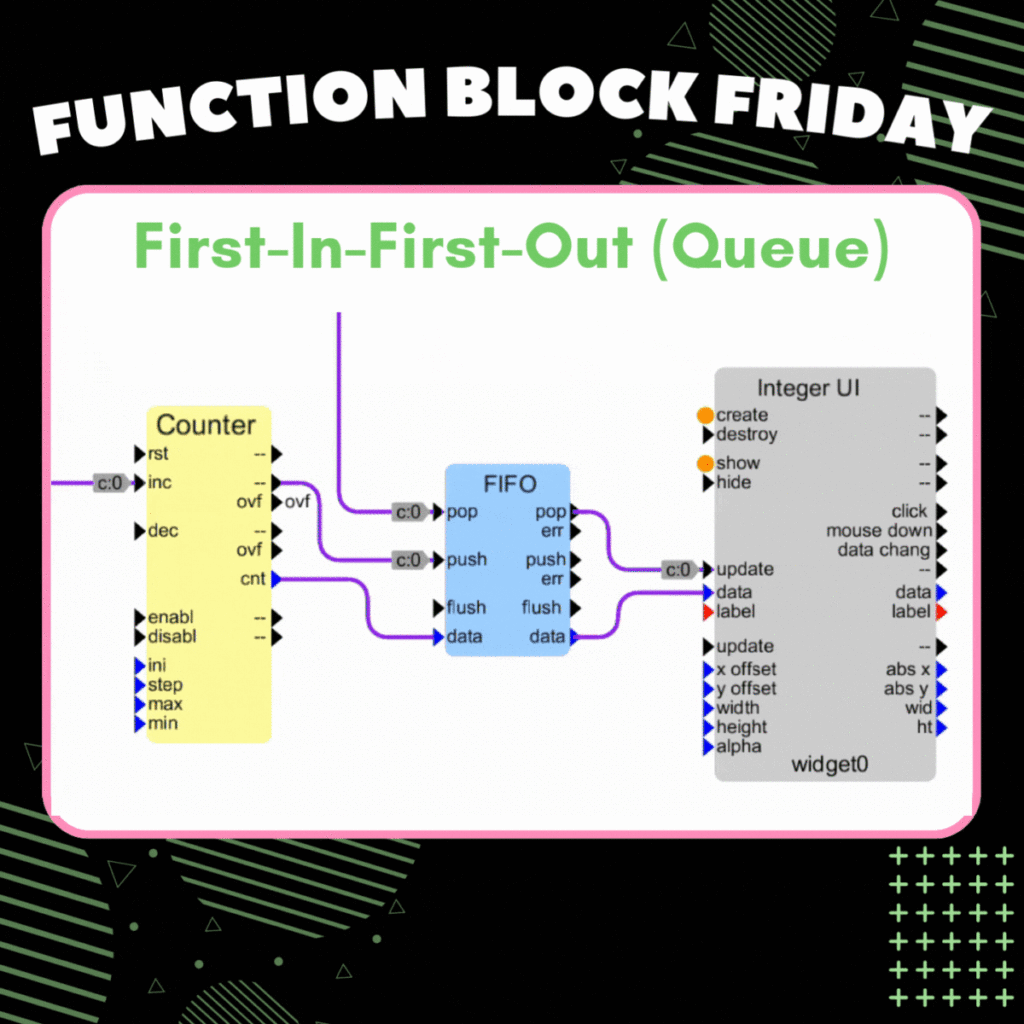
FIFO:
The FIFO Buffer operates on a “first in, first out” principle, ideal for managing streams of data from asynchronous sources that need to be processed one at a time. Think of it as a queue of people waiting in line – the first person to join the queue is the first to leave (we are a UK company so we love queueing!).
LIFO:
A LIFO buffer is often referred to as a stack, like a stack of papers on a desk, where the most recent data pushed is popped first. These are less common, but for example, can model a physical system resembling a stack.
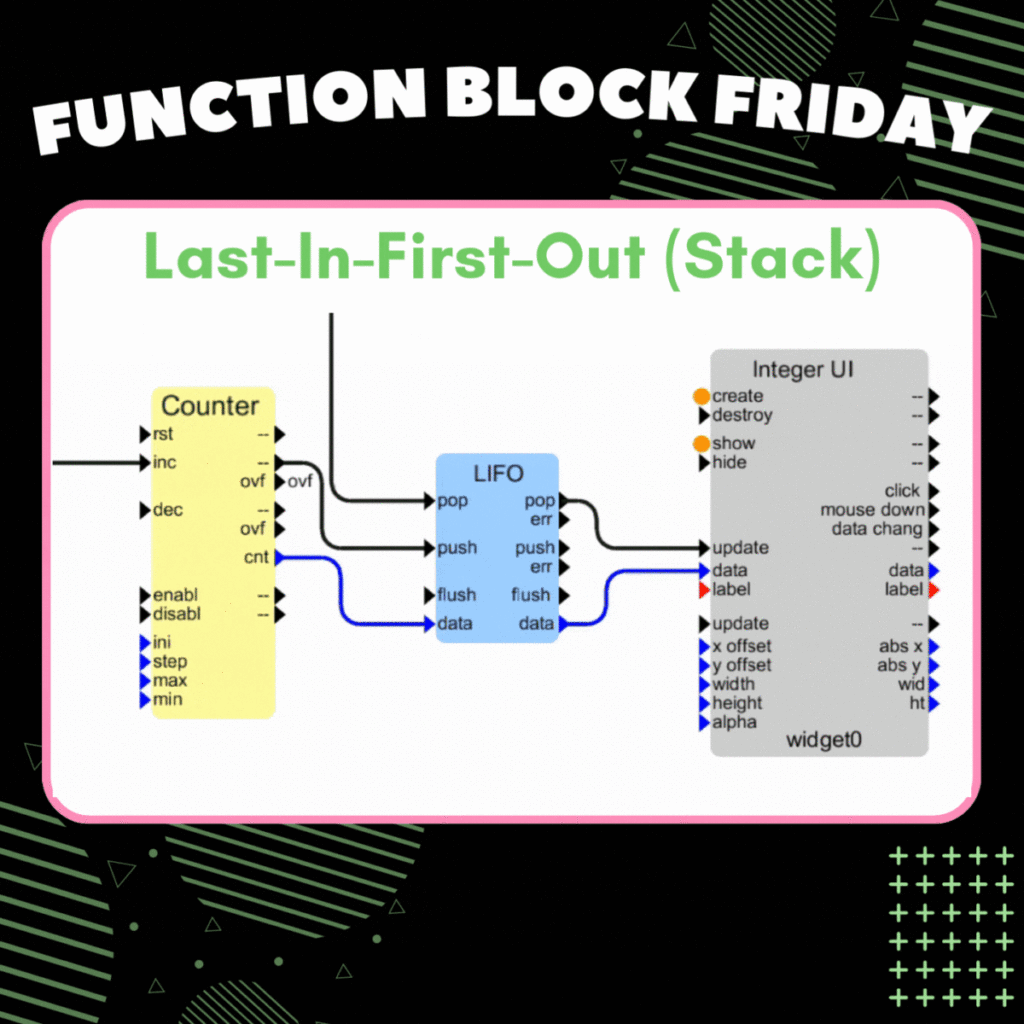
Both FIFO and LIFO buffers share the same set of operations:
Key capabilities:
– Push: Add a new element to the buffer
– Pop: Remove and return an element from the buffer (oldest for FIFO, newest for LIFO)
– Flush: Clear all elements from the buffer
The difference lies in which element is retrieved when you pop:
– FIFO returns the oldest element (first one pushed)
– LIFO returns the newest element (last one pushed)
Common applications:
1. Data Streaming: Manage incoming data flows in real-time applications
2. Task Management: Implement job queues (FIFO) or call stacks (LIFO) in process control
3. Data Security: ensuring that no data is lost when communicating
Whether building a data processing pipeline, managing system resources, or implementing algorithms, these Buffer Function Blocks provide straightforward yet powerful ways to handle data storage and retrieval. Their simplicity makes them versatile tools for a wide range of scenarios where ordered data management is crucial, allowing you to control the flow of information in your applications with precision and efficiency.